

22 May 2017 Spotlight on IBM
There are many impactful Apache Software Foundation projects. A few notable ones are Hadoop (storing/analyzing varieties and volumes of data), HTTP (notice the recognizeable HTTP in website URLs like the one on LinkedIn right now), Cassandra (your favourite apps may be running on this database).
Who is Apache, the organization that supports these projects? Apache is a collaborative community of developers. Open source means you can see the code and modify it.
What’s the next big thing for Apache? Spark!
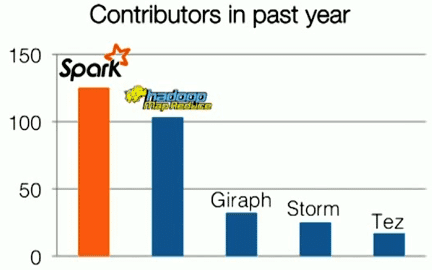
Spark surpassed in Hadoop in 2014, as displayed by this graph
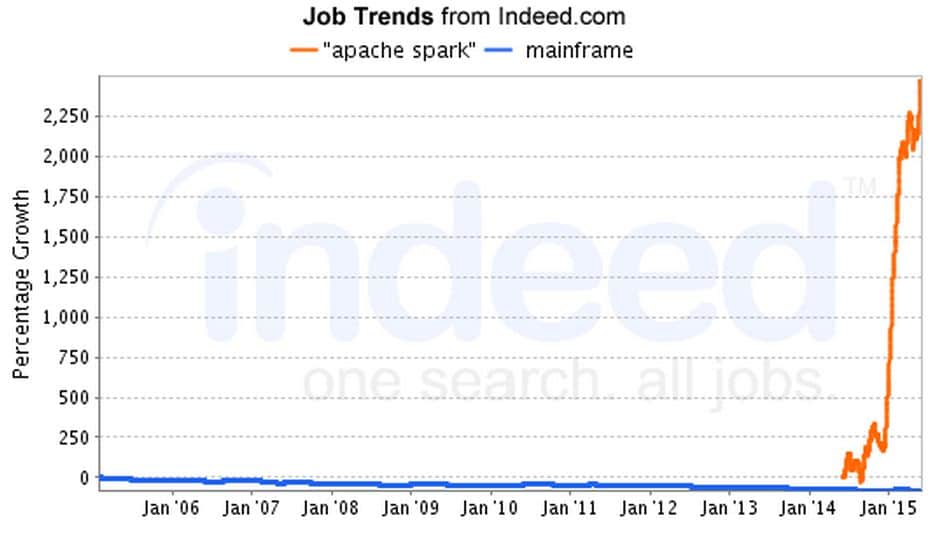
2015 is the year where Spark job postings substantially grew
So, what is Spark?
- Created in response to the limitations of Hadoop’s MapReduce’s external disk input/output (i/o) by working in-memory
- A distributed computing framework with distributed meaning nodes completing jobs in parallel
- Leverages resilient distributed datasets (RDD) which are partitions of data stores that are shareable and can be computed on different machines
Why is Spark great?
- Spark works in-memory instead of the constant external disk i/o which is expensive as there are many steps that makes analysis slow (even weeks) and time is money
- Up to 100x faster than Hadoop’s MapReduce
- Rich machine learning libraries
- Ideal for streaming, near real-time analytics
- GraphX, for distributed graph/network analytics
- SparkSQL, faster than most Hadoop SQL engines
- In a nutshell: the most advanced and speediest analytics
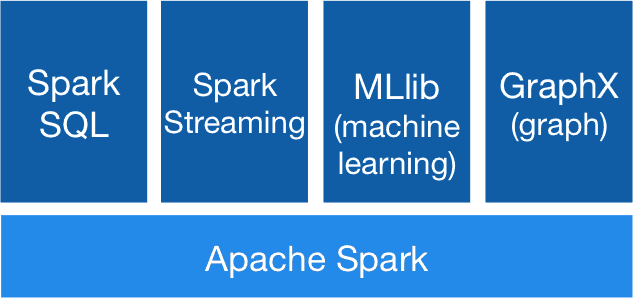
What are Spark’s Use Cases?
We now understand what Spark is and why its great. But how it impact businesses? There are a variety of use cases but I’ll keep it to a few for time purposes.
- Machine learning: recommendations (ex. Netflix), sentiment analysis, segmentation
- Streaming/near real-time: fraud, network security, ETL, IoT, smarter homes/cities
- GraphX: social networks, website analytics (Google’s PageRank), location analytics
How can I get Spark Today?
Spark is like a car; lots of utility but hard to build and maintain.
There are two ways to do this. The first choice is you build and manage it yourself. The second is to partner with an expert.
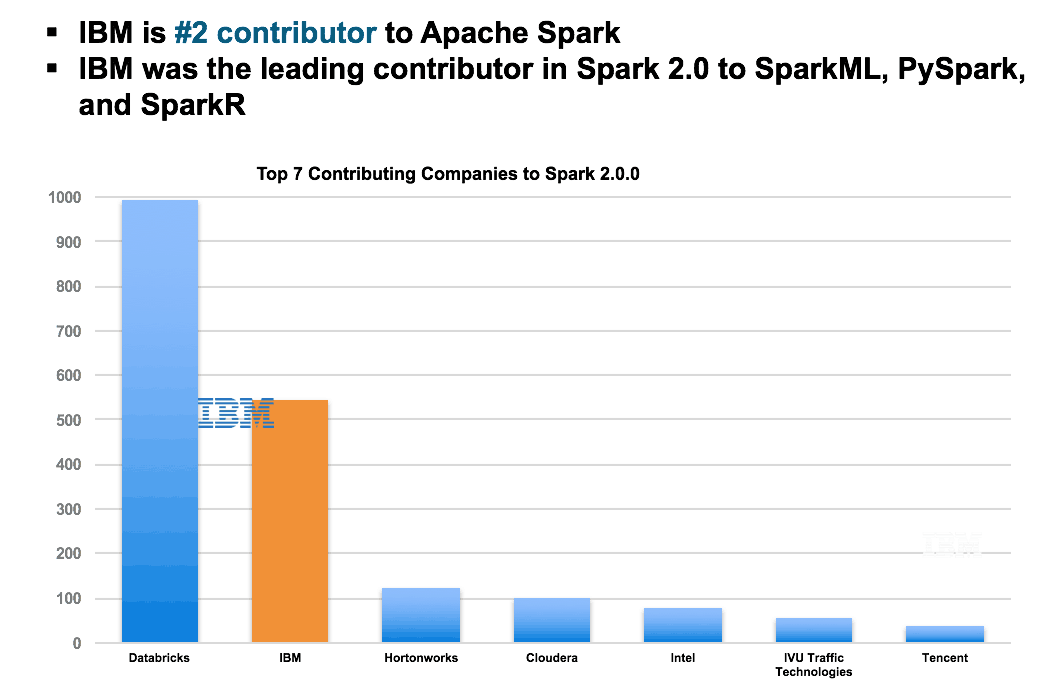
At IBM, we’re the second largest contributor to Apache Spark, larger than the next 5 vendors combined, and aiming to be first. We’re a co-founder of the Spark Technology Centre where we have over 300 engineers just contributing to Spark code.
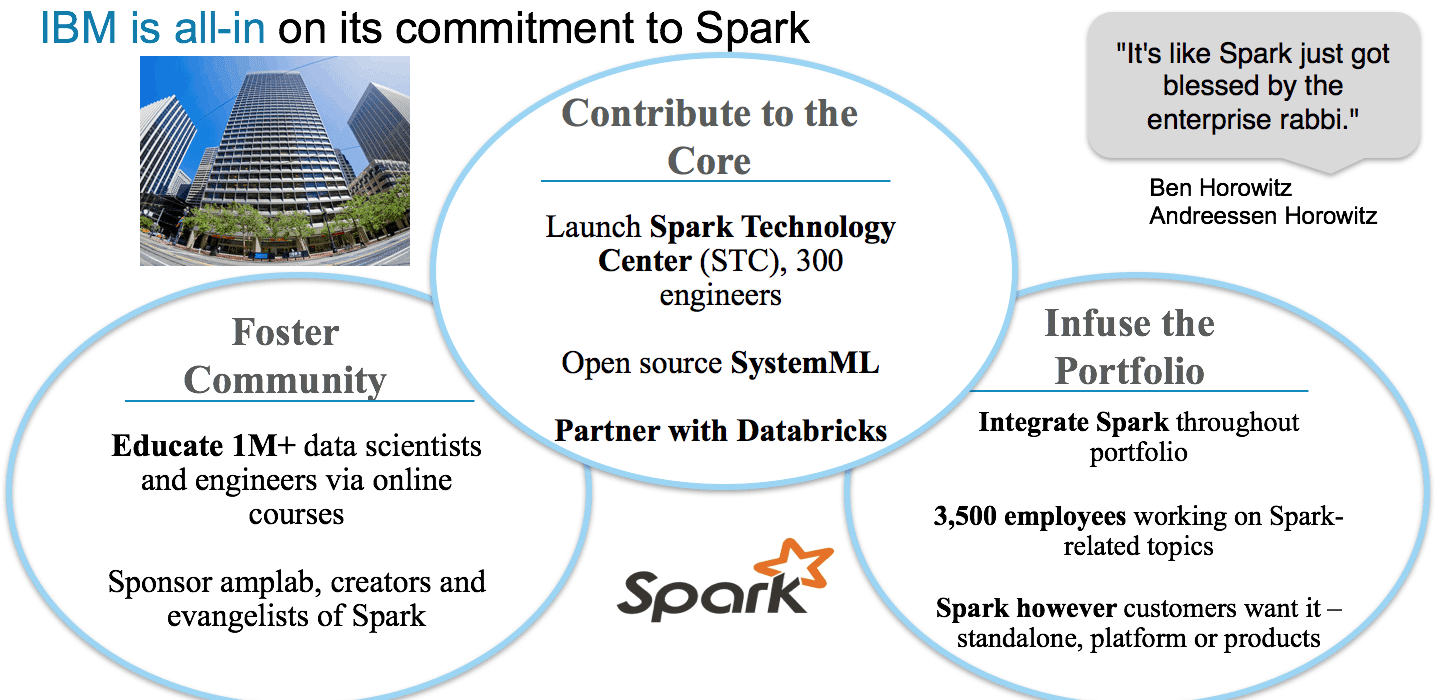
This means we understand Spark, can give expertise, and power our platforms with it like in the Data Science Experience (try DSX free), a data science development platform. Gartner, the industry standard for IT ratings, gave us the top position for data science platforms, and the Data Science Experience was a big reason.
8 Reasons Why the DSX Received the Highest Rating
1). Powered by a Spark-as-a-service cluster
2). Allows RStudio and Jupyter Notebooks, the notebook for the biggest community paving the way for continuous innovation and support, to send Spark jobs
3). Real-time collaboration
4). Integrates GitHub community to easily import code and learn from previous projects
5). Connections to many data sources to avoid vendor lock-in
6). Work with SPSS Models in the same environment
7). Use CPLEX for linear optimization
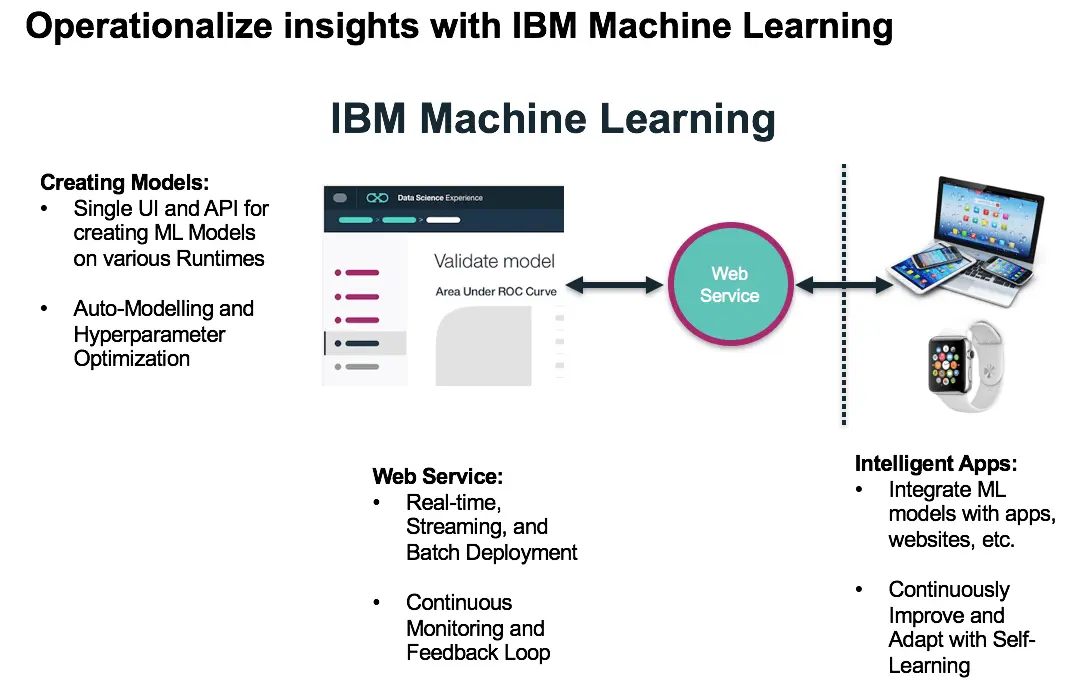
8) IBM Machine Learning as-a-service
How Do I Learn More?
We understand that Spark is cutting-edge and nobody is an expert. We’re here to help. Send me a message and I’ll be happy to help you with your Spark journey.
